|
|

|

|
| e-Pub |
Section: New Results
Learning and statistical models
Kernel-Based Methods for Hypothesis Testing: A Unified View
Participants : Zaid Harchaoui, Francis Bach, Olivier Cappe, Eric Moulines.
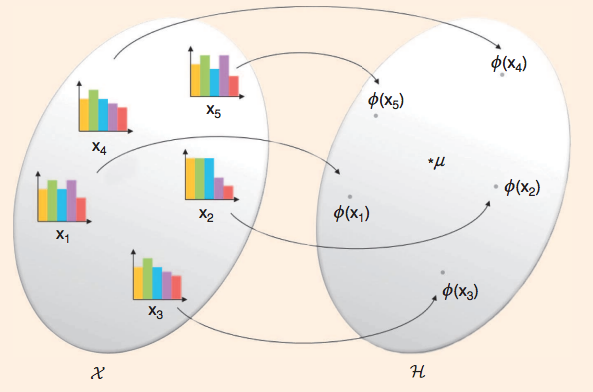
Kernel-based methods provide a rich and elegant framework for developing nonparametric detection procedures for signal processing. Several recently proposed procedures can be simply described using basic concepts of reproducing kernel Hilbert space embeddings of probability distributions, namely mean elements and covariance operators. In [5] , we propose a unified view of these tools, and draw relationships with information divergences between distributions (see Figure 4 ).
Supervised Feature Selection in Graphs with Path Coding Penalties and Network Flows
Participants : Julien Mairal, Bin Yu.
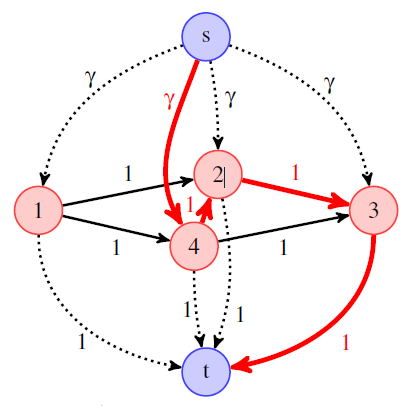
In this paper [6] , we consider supervised learning problems where the features are embedded in a graph, such as gene expressions in a gene network. In this context, it is of much interest to automatically select a subgraph with few connected components; by exploiting prior knowledge, one can indeed improve the prediction performance or obtain results that are easier to interpret. Regularization or penalty functions for selecting features in graphs have recently been proposed, but they raise new algorithmic challenges. For example, they typically require solving a combinatorially hard selection problem among all connected subgraphs. In this paper, we propose computationally feasible strategies to select a sparse and well-connected subset of features sitting on a directed acyclic graph (DAG), see Figure 5 . We introduce structured sparsity penalties over paths on a DAG called “path coding” penalties. Unlike existing regularization functions that model long-range interactions between features in a graph, path coding penalties are tractable. The penalties and their proximal operators involve path selection problems, which we efficiently solve by leveraging network flow optimization. We experimentally show on synthetic, image, and genomic data that our approach is scalable and leads to more connected subgraphs than other regularization functions for graphs.
Structured Penalties for Log-linear Language Models
Participants : Anil Nelakanti, Cédric Archambeau, Julien Mairal, Francis Bach, Guillaume Bouchard.
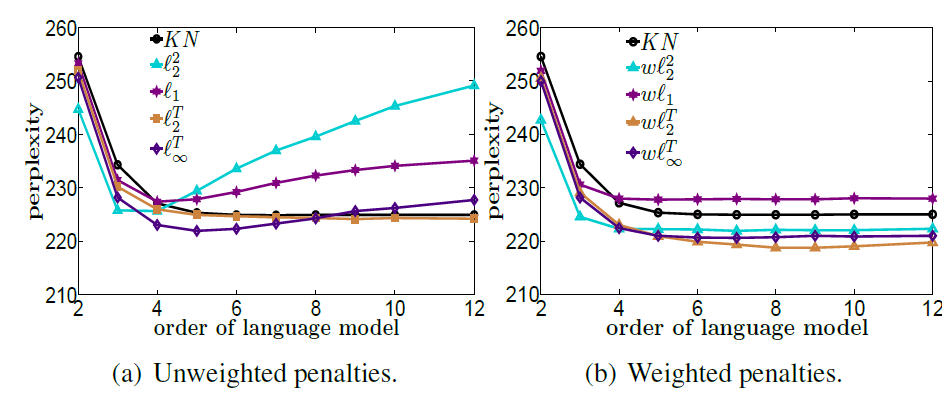
Language models can be formalized as loglinear regression models where the input features represent previously observed contexts up to a certain length . The complexity of existing algorithms to learn the parameters by maximum likelihood scale linearly in , where is the length of the training corpus and is the number of observed features. In this paper [26] , we present a model that grows logarithmically in , making it possible to efficiently leverage longer contexts (see Figure 6 ). We account for the sequential structure of natural language using tree-structured penalized objectives to avoid overfitting and achieve better generalization.
|
Optimization with First-Order Surrogate Functions
Participant : Julien Mairal.
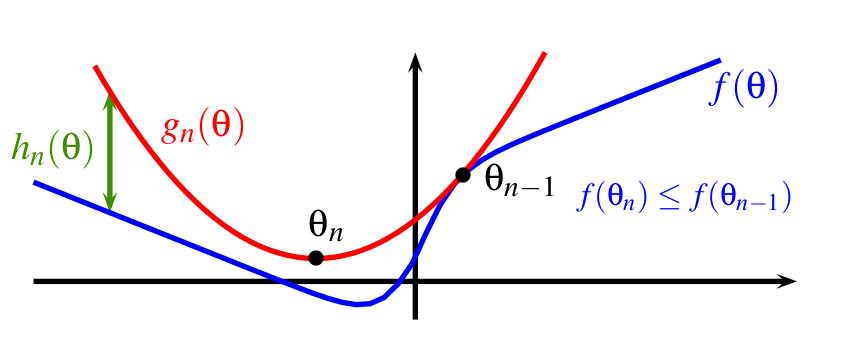
In this paper [23] , we study optimization methods consisting of iteratively minimizing surrogates of an objective function, as illustrated in Figure 7 . By proposing several algorithmic variants and simple convergence analyses, we make two main contributions. First, we provide a unified viewpoint for several first-order optimization techniques such as accelerated proximal gradient, block coordinate descent, or Frank-Wolfe algorithms. Second, we introduce a new incremental scheme that experimentally matches or outperforms state-of-the-art solvers for large-scale optimization problems typically arising in machine learning.
|
Stochastic Majorization-Minimization Algorithms for Large-Scale Optimization
Participant : Julien Mairal.
Majorization-minimization algorithms consist of iteratively minimizing amajorizing surrogate of an objective function. Because of its simplicity and its wide applicability, this principle has been very popular in statistics and in signal processing. In this paper [24] , we intend to make this principle scalable. We introduce a stochastic majorization-minimization scheme which is able to deal with largescale or possibly infinite data sets. When applied to convex optimization problems under suitable assumptions, we show that it achieves an expected convergence rate of after iterations, and of for strongly convex functions. Equally important, our scheme almost surely converges to stationary points for a large class of non-convex problems. We develop several efficient algorithms based on our framework. First, we propose a new stochastic proximal gradient method, which experimentally matches state-of-the-art solvers for large-scale - logistic regression. Second, we develop an online DC programming algorithm for non-convex sparse estimation. Finally, we demonstrate the effectiveness of our approach for solving large-scale structured matrix factorization problems.